ISRI's ``Sample 1'' Database![]() consists of 240 pages
selected at random. Only the text portions of each page were zoned
and then each image was processed by six OCR devices [11].
consists of 240 pages
selected at random. Only the text portions of each page were zoned
and then each image was processed by six OCR devices [11].
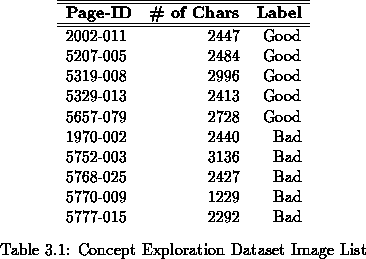
For the concept exploration dataset 10 pages were selected from the Sample 1 database. Sample 1 was divided into 3 quality groups [11] and 5 pages were selected from groups 1 and 3, respectively. Table 3.1 lists the Concept Exploration Dataset pages with their assigned ``Good'' or ``Bad'' labels.