Figure 4.1 shows modules in the classifier. The ccomp program generates the black and white connected components from a TIFF image file. The two CC files are then read by the clas program which calculates the features, applies the classification rules, and generates the results file, from where the reports are then extracted.
The accuracy value from the OCR processing of the image is used only for generating the output tables and is not used by the classifier's logic in any other way.
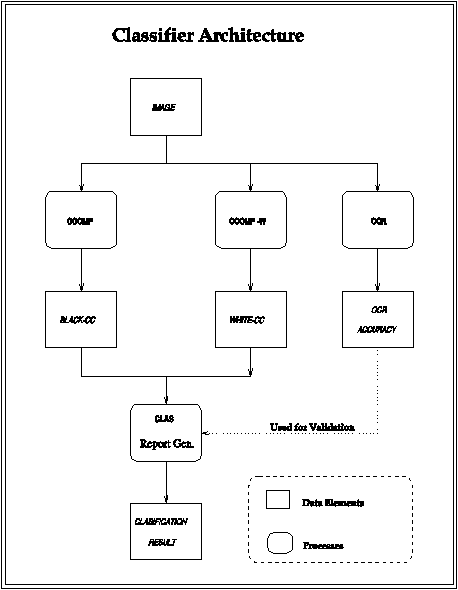
Figure 4.11: Classifier Logic Architecture
To automate the testing of a large number of images, the following steps are followed:
The reports and confusion matrices are generated automatically from the results file. The scripts to perform these tasks are written in the PERL programming language [17]. The connected components finder is written in C, as is the feature extractor from the CC data. The whole process is driven by a PERL script which produces the result file.