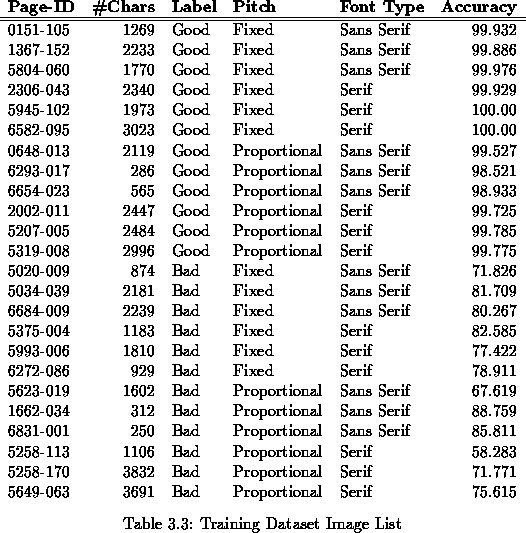
Training Dataset



Next: Conclusions from Training
Up: Determining Threshold Values
Previous: Determining Threshold Values
Because of the geometric nature of the features, a more heterogeneous
training dataset was needed. The concept exploration dataset lacked
several font and pitch combinations; the features proposed can be
affected by size variations. The training dataset was
constructed with the following characteristics:
- Twenty four pages total, with 12 ``good'' and 12 ``bad'',
where the meaning for ``good'' is an OCR median accuracy of at least
90%.
- Three pages were re-used from the concept exploration dataset
and 21 new ones were selected from ISRI's ``Sample
2''
 database.
database.
- The pages were selected based on their median OCR accuracy (see
below), font type and pitch. All the combinations were constructed and
3 pages were selected for each combination (see
Table 3.3). The median accuracy was computed from the
output of eight OCR devices (see Table 4.1) except for pages
2002-011, 5207-005 and 5319-008 that were processed
by the devices listed in Table 3.2.
- Whenever possible, pages containing at least 500 characters
were selected.
- Only text zones were considered. Tables and graphs were
ignored.


The reason for using median accuracy instead of the mean accuracy is
that the median measure is a more stable metric, since it is not
affected by abrupt lows or highs in accuracy for any device. The mean
value, on the other hand, would be affected by such a behaviour and
thus would render an accuracy value that is not representative of the
``general'' accuracy OCR devices have on the page.