Features Observed but not Used



Next: New Datasets
Up: Future Work
Previous: Statistical Pattern Recognition
The use of new and more complex features would be a key component in a
production-type classifier. Specifically if the user is interested in
higher ``good thresholds'', more features will be needed for the
filter to use.
While performing the research for this thesis, several features were
discovered which could be useful in a full-blown system. These
features along with a brief explanation of their significance follow:
- Overlapping. The amount of overlapping between two
neighboring connected components' boxes could serve as an indicator of
both the font complexity and of deformed and/or broken characters (see
Observation 5 in Chapter 3).
- Skew angle. The degree of skew of an image could very
well be a strong indicator of the quality of the image. If the skew
degree is more than a certain threshold [13] then the page
should be considered ``Bad''.
- Width distribution. In order to determine the amount of
touchiness in a page, the width distribution would probably have to be
calculated and information compiled from that calculation.
- Micro-Gaps. In this work, very small white blobs were
used to estimate the degree of thickness (and therefore touchiness)
the characters have. In the same vein, a metric to detect
micro-gaps
 would account for a large amount the broken characters and
also for the degree of character complexity (see Observation 4 in
Chapter 3).
would account for a large amount the broken characters and
also for the degree of character complexity (see Observation 4 in
Chapter 3).
- Filled CC boxes. A way to detect completely filled lakes
in letters like ``e'', ``a'', etc, would be to measure the black
density inside a CC box of certain (minimum)
dimensions. Figure 5.1 shows an example of this metric in
action for two real-word string of characters. The black densities of
each connected component, and for the collection of connected
components, are shown for a ``fat'' and a ``normal'' character strings.

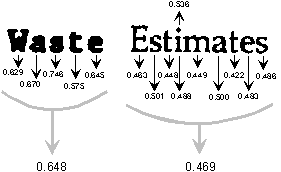
Figure 5.1: Black Density for Connected Components
- Deformed contours. The degree of complexity of the
contours of a character could also be a very good predictor of the
font complexity and the paper/scanner quality. Figure 5.2
shows a ``well-formed'' and a ``deformed'' character.
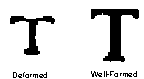
Figure 5.2: Deformed and Well-Formed Characters
Next: New Datasets
Up: Future Work
Previous: Statistical Pattern Recognition