Two hundred magazine pages were also run through the classifier to test its performance. Magazine pages are very different to standard ``document-type'' pages because they often contain artistic fonts, graphs, color, etc. The difference between these pages and the ones used to create the classifier make the magazine dataset a perfect choice for testing the classifier's performance in a different environment.
The magazine dataset consists of 200 pages taken from the top 100
magazines in the US, according to their circulation. Two pages were
randomly selected from each magazine and each page was clipped out,
scanned in, and the truth text file was generated. All the pages
were manually zoned. All parts of the page zoned except for commercial
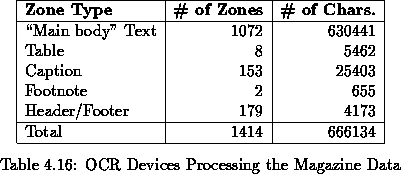
advertisments and pictures [13]. Table 4.16 lists the
types of zones used in the preparation of this
data![]() . Each page
was processed by 6 OCR devices and, as with the test dataset, the
median accuracy was computed. Table 4.17 lists the devices
used.
. Each page
was processed by 6 OCR devices and, as with the test dataset, the
median accuracy was computed. Table 4.17 lists the devices
used.

All 200 pages were processed by the classifier without pre-filtering. The confusion matrices for ``good thresholds'' of 90%, 95%and 98%are shown in Tables 4.18, 4.19, 4.20, respectively. Appendix B contains the complete classification results for all 200 pages.
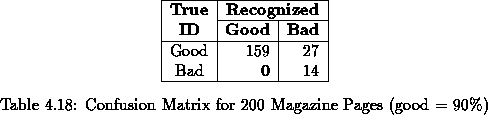
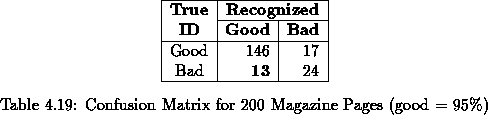
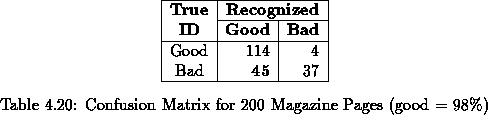
The error rates for each good threshold are:
The classifier did very well on the 90%threshold because it did not
incur in any BG misclassifications. As expected, its
performance degraded at the higher thresholds.
The classifier was then modified as suggested by the results obtained with the test dataset. Consequently, the Black CC Size rule (Rule #3) was disabled and the magazine dataset was again run through the classifier. The confusion matrix is presented in Table 4.21 and, contrary to what was expected, the error rate went up and the number of misclassifications remained the same (compare Tables 4.18 and 4.21). Based on the results, Rule #3 works well for the magazine dataset but poorly for the test dataset. This preliminary evidence suggests that generalizations cannot be made about the behavior of the classifier in a different environment.
