After conducting an extensive literature survey and consulting with various researchers in the OCR field, no previous work similar to the one presented here could be found. Therefore, alternative approaches to OCR difficulty evaluation were investigated. These works, even though not aimed at finding page quality metrics, are closely related to this project's scope.
Mindy Bokser presents a complete view of the problems associated with trying to recognize letters from a page image [3]. According to her work, touching and broken (split) characters seem to be the most important source of OCR problems. Regarding OCR technology, she acknowledges that
The best products do a good job on clean documents, but they all degrade in performance -some more gracefully than others- as document quality (or scanner quality) degrades [3].
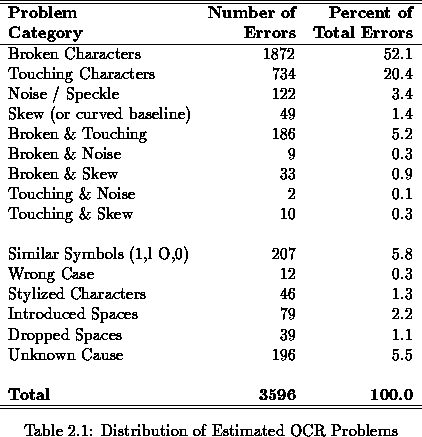
Similarly, Nartker et al [8] identified broken and touching
characters as the leading cause of OCR
errors. Table 2.1![]() summarizes estimated OCR problems obtained from a
240-page test. Page quality errors account for
83.9%of the total number of errors in the set, whereas errors caused
by other factors account for the rest.
summarizes estimated OCR problems obtained from a
240-page test. Page quality errors account for
83.9%of the total number of errors in the set, whereas errors caused
by other factors account for the rest.
Jenkins and Kanai [5] studied the influence of lexical
factors on OCR performance. They controlled image quality and
typographical features by creating synthetic images and using them as
input to OCR devices. Based on their results, they suggested that
linguistic factors, apart from image-related factors, also affect OCR
performance, since most current OCR products incorporate a system
lexicon to resolve character recognition ambiguity. Along this idea,
the number of stopwords![]() was
identified as a factor in OCR accuracy, since they are more likely to
be included in the system's lexicon than non-stopwords.
was
identified as a factor in OCR accuracy, since they are more likely to
be included in the system's lexicon than non-stopwords.
An important point to be made is that a high percent of the errors are due to relatively few causes, which ultimately correspond to image quality, whereas a large number of other factors represent a relatively low number of errors. Therefore, methods and solutions for image quality problems can and will have a direct impact on OCR performance from an end-user's point of view, since by fixing page-quality related errors the accuracy rate can increase considerably.