Digital information storage has become commonplace mainly because of the growth of computer technology. There is a growing trend among publishers to offer digital versions of their products. Nevertheless, as stated in [7], printed versions of documents will always be needed and, more importantly, there will always be a need to convert these printed documents into their digital counterparts.
A document image is a visual representation of a printed page, such as a journal article page, a magazine cover, a newspaper page, etc. Typically, a page consists of blocks of text, i.e. letters, words, and sentences that are interspersed with half tone pictures, line drawings, and symbolic icons. A digital document image is a two-dimensional numerical array representation of a document image obtained by optically scanning and raster digitizing a hard copy document. It may also be an electronic version that was created in that form, say, for a bit-mapped screen or a laser printer [15].
The process of transforming a printed document image into a digital
document consists in the spatial sampling and simultaneous conversion
of light photons to electric signals. This process is carried out by a
``scanner'', which in essence divides the printed page into small
pixels![]() and samples a light
value for each of these pixels on the page. This value is then
thresholded against a pre-set value to determine whether or not that
particular pixel will be considered ``filled''
and samples a light
value for each of these pixels on the page. This value is then
thresholded against a pre-set value to determine whether or not that
particular pixel will be considered ``filled''![]() .
.
Scan resolution is very important. The width of a typical character stroke is about 0.2mm (0.008 inch), with some of the widest strokes up to about 1mm. A 10-point character measures about 0.5mm (0.014 inch) between ascender and descender lines. A sampling rate of 240 ppicorresponds to about 0.1 mm/pixel, which guarantees that at least one pixel will fall totally within the stroke [15]
Two of the main advantanges of having textual information rather than page images stored are the possibility of searching large amounts of information and the ease in retrieving only what is relevant to a query. There are several ways of querying a body of information; a discipline that studies these related aspects is called Information Retrieval. In order to generate the information to accomodate these queries, the image file is not enough. The image file only contains a digital representation of the ``look'' of a printed page but lacks understanding of any of its contents. Since information retrieval requires the contents in order to perform the retrieval, a way to extract these contents of the digital image is necessary.
Desktop Publishing (DTP) applications comprise another important reason to have information stored digitally. To accomodate the task of edition and modification a DTP system must handle the textual representation of the information in order to edit and format it. Having only the information as a picture prevents the DTP application from doing any editing or layout formatting because the image format is not suited for these operations.
There are other reasons motivating the extraction of contents from an image page besides the possibility of retrieval, cataloguing, and DTP. One very important aspect is that, in general, the digital version of the contents of a page usually occupy less space than the image file. Furthermore, if the content is textual information and the representation selected is a text file (as is usually the case), the content can be electronically mailed and distributed, not to mention modified, whereas any of these tasks would be difficult at best if working with the image file only.
Optical Character Recognition (OCR) is the process by which a page image is transformed into a text file. The purpose of the whole OCR process is to recognize the letters, words, and symbols printed on a page. Presently, there are many commercial OCR systems in use.
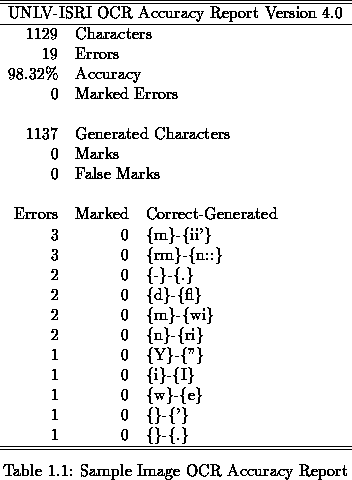
OCR systems usually first receive a page image as input, then they segment out characters, and finally they recognize these characters. Additionally, OCR systems may use spell checkers or other lexical analyzers that make use of context information to correct recognition errors and resolve ambiguities in the generated text. The output of the OCR process is a text file, corresponding to the printed text in the image file. Figures 1.1 and 1.2 show an example of a small image file and its corresponding OCR output, respectively.

Figure 1.1: Sample Image File

The Information Science Research Institute (ISRI) has developed a set
of tools to automate the measurement of character recognition accuracy
from the OCR generated output [14]. Table 1.1
shows the number of OCR-generated errors from Figure 1.2 and
the character accuracy![]() .
.
Measuring OCR accuracy has become the universally accepted way of rating OCR devices' performance [13][12][11]. It is a good measure because, among other things, it correlates nicely with the end-user's perspective. Higher accuracy means better recognition and less work (cost) to correct OCR-generated errors.